Matemáticas
, Cómputo
I. De Listas Doblemente Enlazadas a 2-Variedades

Muchas cosas en esta vida las damos por sentado: el tiempo, el dinero, las relaciones, pero principalmente los kerneles geométricos. Industrias enteras colapsarían sin estos módulos ya que programas como AutoCAD, Unity o Blender dependen de ellos para realizar sus funciones más básicas1.
Un kernel geométrico es, en esencia, una librería (usualmente escrita en C++) que se encarga de representar y modificar superficies combinatorias. Pensemos en un ejemplo muy sencillo, abres Blender, seleccionas el cubo, presionas <tab> para entrar al modo edición, seleccionas una cara y presionas E para extruirle. ¿Alguna vez te has preguntado qué tiene que suceder para poder llevar a cabo esta sucesión de pasos?
Si Blender no fuera de código abierto llegaría a pensar que esto sucede gracias a algún tipo de magia.
Simplificando demasiado, necesitas de una estructura de datos que te permita representar al cubo y también de un algoritmo que modifique esa estructura eficientemente. Hoy quiero escribir sobre la primer parte: la representación.
Mi intención es explicar cómo se suelen representar a las variedades topológicas en memoria a lo largo de una serie de artículos cuya extensión sea digerible. Esta serie de artículos nace de mi interés por la geometría diferencial discreta y la geometría conforme computacional2.
Sin falla alguna encuentro un gesto de sorpresa cada que menciono la existencia de la geometría diferencial discreta, algo que adoro pues fue mi misma reacción cuando me encontré con el trabajo de Keenan Crane. La pregunta que guía el desarrollo de esta área de estudio es simple:
¿Cómo podemos traducir todos los avances en geometría diferencial a un lenguaje que nos permita aplastarlos y colocarlos en nuestras computadoras?
La respuesta, por otro lado, no lo es.
El objeto más básico de la geometría diferencial es el de variedad y en este artículo quiero hablar sobre una de sus discretizaciones: la malla de semi-aristas. Mi intención es que esto sea auto-contenido y el único requisito para leerle sea un grado razonable de imaginación y un nivel de madurez matemática post-rigor, como nos cuenta Terence Tao.
Comencemos con una forma ineficiente de representar una superficie combinatoria.
Matrices de Adyacencia.
Expliquemos la idea detrás de las matrices de adyacencia usando un complejo simplicial muy simple, el triángulo. Nuestro objetivo es separar los componentes del complejo por dimensión y representar la relación entre los que tienen dimensión con los que tienen dimensión usando una matriz que denotaremos .
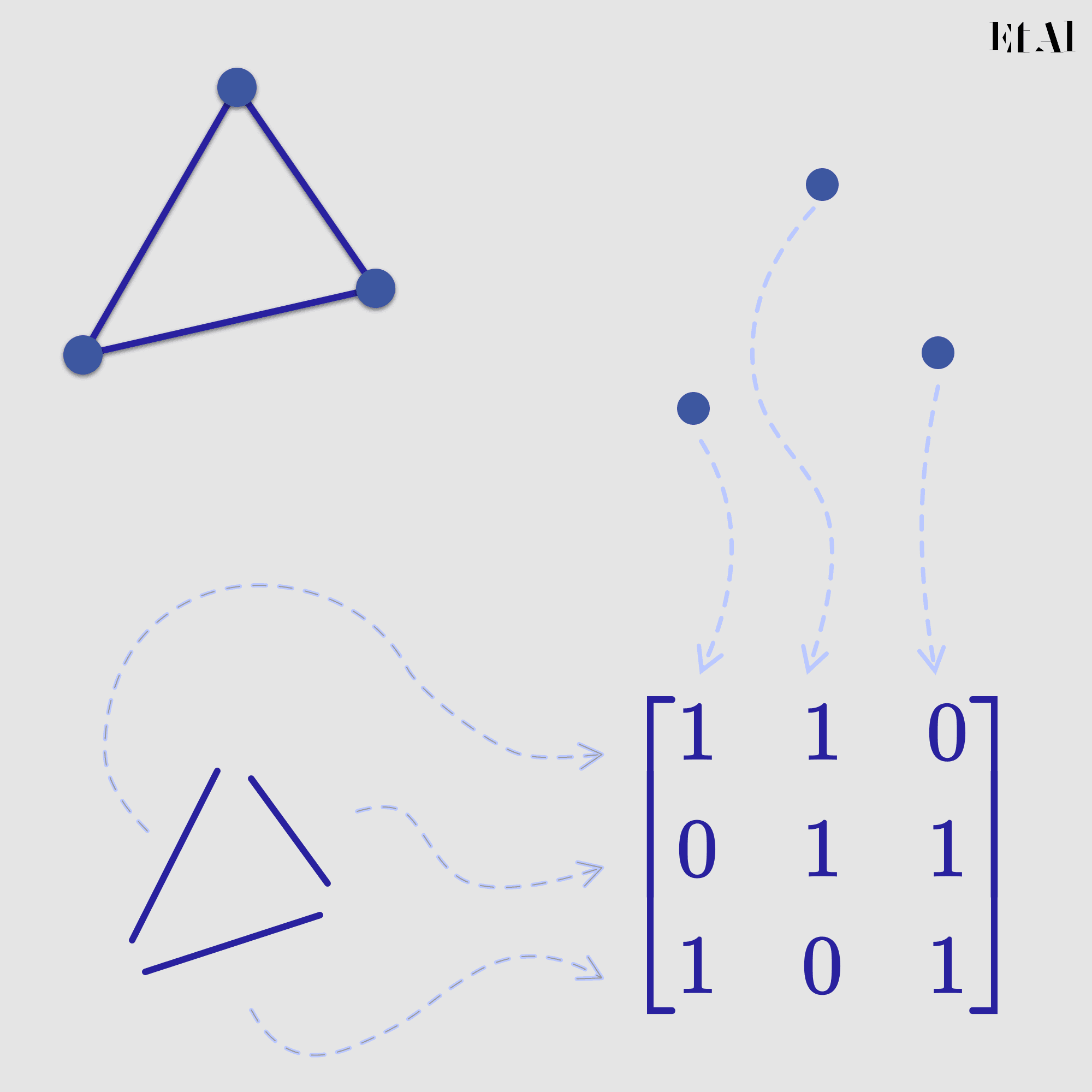
Representando al triángulo con una matriz de adjacencia.
Aquí tenemos una matriz cuyas filas son las artistas y las columnas son los vértices, cada entrada es uno si la -ésima arista es adyacente a el -ésimo vértice y es cero de lo contrario. No es más complicado que esto y confío en que puedes imaginar como se extiende naturalmente para complejos simpliciales de dimensión mayor.
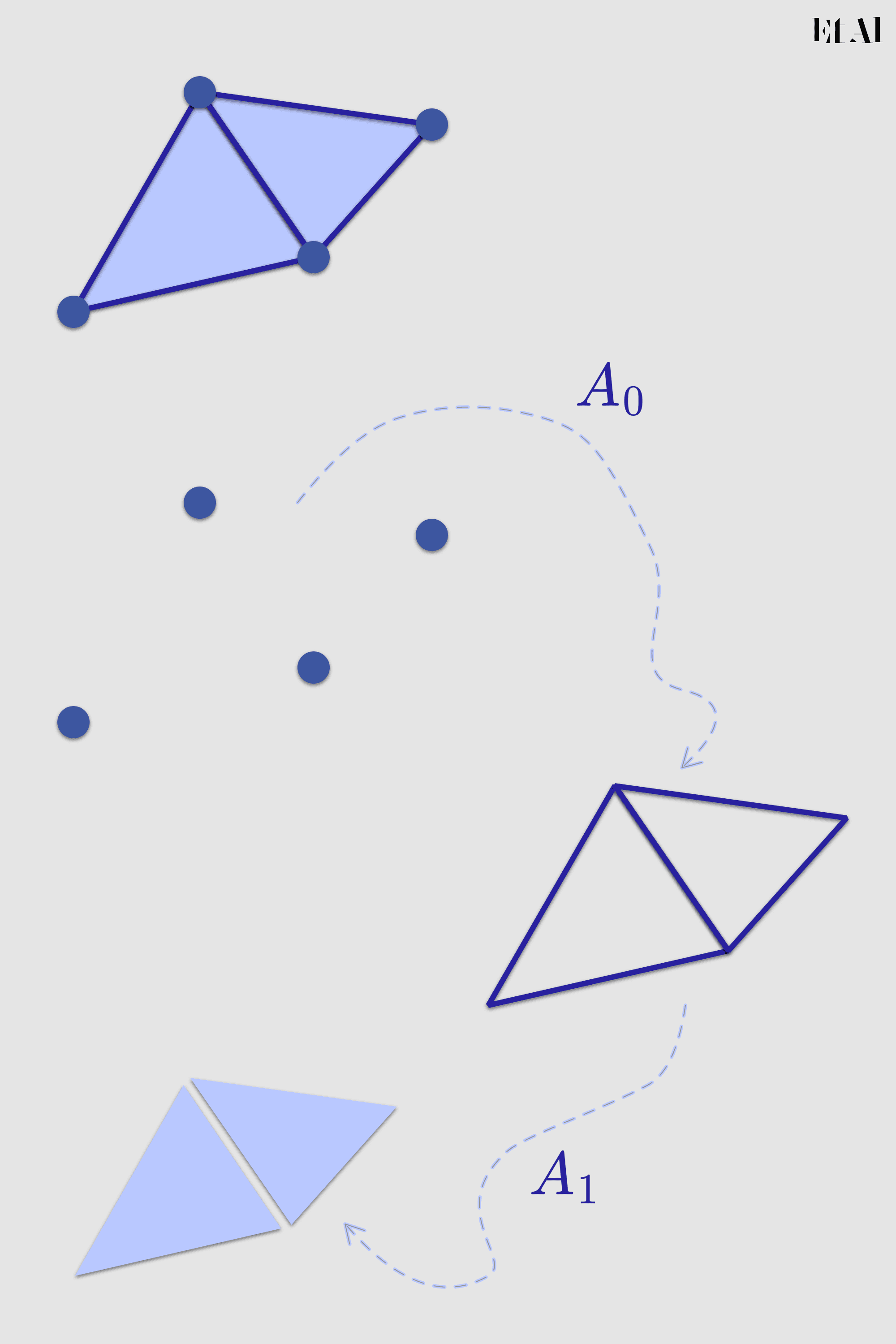
Utilizamos dos matrices para representar la topología del complejo.
¿Y cuál es el problema con esto?
Dame una estructura de datos y yo te daré diez quejas. Supón que queremos hacer algo tan simple como borrar un vértice ¿qué serie de pasos tenemos que llevar a cabo para lograrlo?
Pensemos en nuestra situación, si borras un vértice tienes que borrar las aristas que inciden en este vértice y si borras las aristas tienes que borrar las caras adyacentes y si borras las caras tienes que borrar los volúmenes adyacentes y si borras los volúmenes, pues, ya te imaginas el resto.
Al principio de este proceso consultamos a la matriz preguntando ¿qué aristas son adyacentes a mi vértice? Esto lo respondemos recorriendo las entradas de la columna que le corresponde para filtrar las que sean uno, lo cual sucede en .
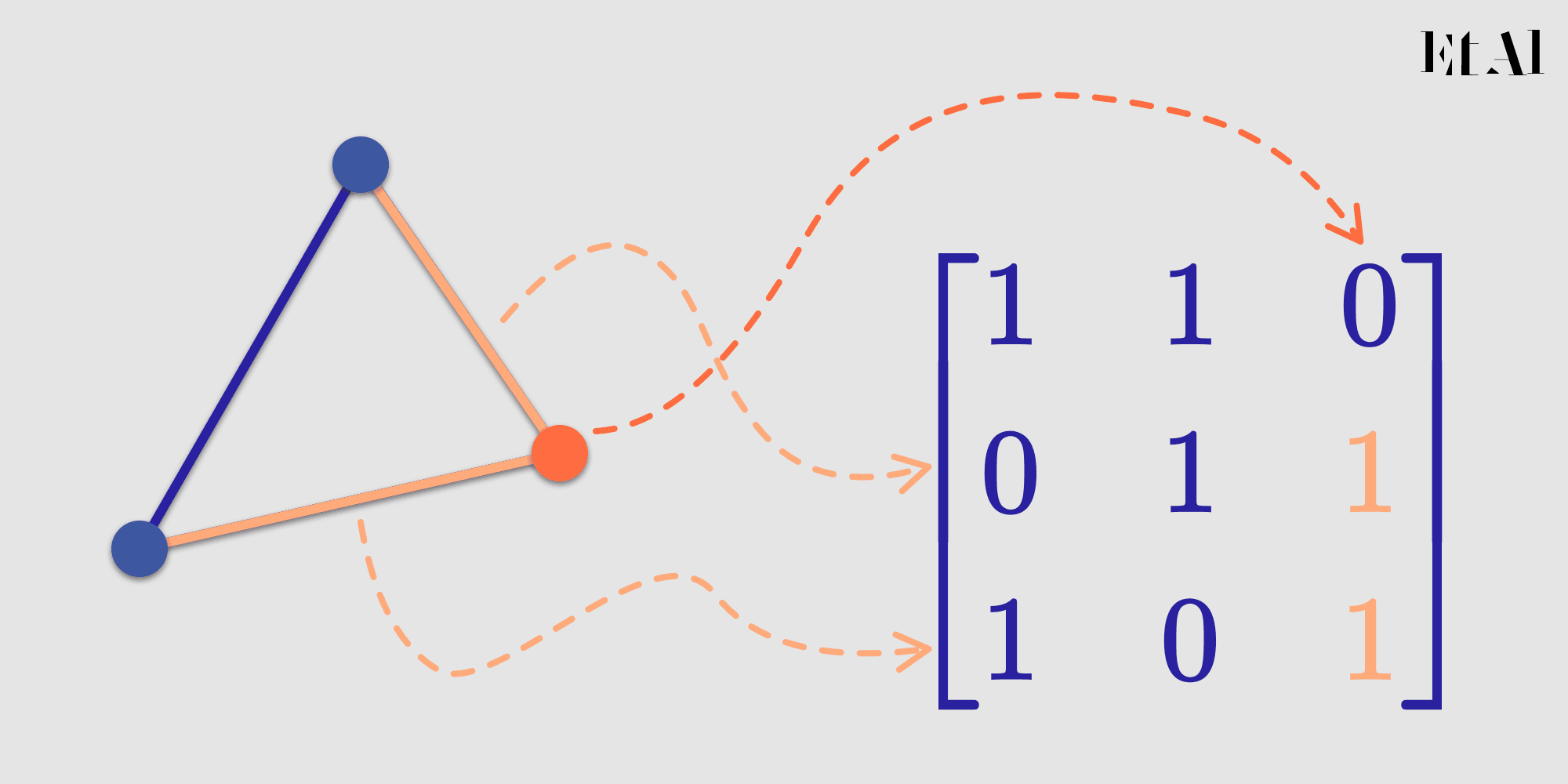
Consultando la matriz
Encontradas las aristas repetimos este proceso para cada una tomándonos .
Llamemos al conjunto de componentes en nuestro complejo que tienen dimensión , por lo argumentado anteriormente es visible que borrar un vértice nos cuesta
una expresión horrible incluso para el caso bibimensional
Esto se vuelve peor cuando notamos que solo estamos buscando, ni siquiera hemos considerado el costo de actualizar las matrices.
El problema con esta representación viene de que solamente guarda información sobre la conexidad entre componentes de dimensiones sucesivas, de modo que si quisiéramos saber cómo se relaciona un vértice con una cara, primero tendríamos que averiguar cómo se relaciona ese vértice con las aristas y después esas aristas con la cara, esto sucede en tiempo lineal en cada caso y el costo se acumula rápidamente.
Afortunadamente resulta ser el caso que podemos volver esta consulta constante modificando una estructura de datos tan inofensiva que es impresionante: la lista enlazada.
¿Qué es una lista enlazada?
Es muy diferente preguntar qué es una lista enlazada que preguntar cómo se le define. Una pregunta es ontológica, mientras que la otra es sobre implementación. Con esto en mente, abordemos la pregunta ontológica.
Una lista enlazada simplemente es una trayectoria dirigida que podemos utilizar para dar un orden total a una colección de objetos .
En términos de implementación, ahora si, se le asigna a cada objeto un apuntador a otro objeto que nos dice "el objeto que va después de es ".
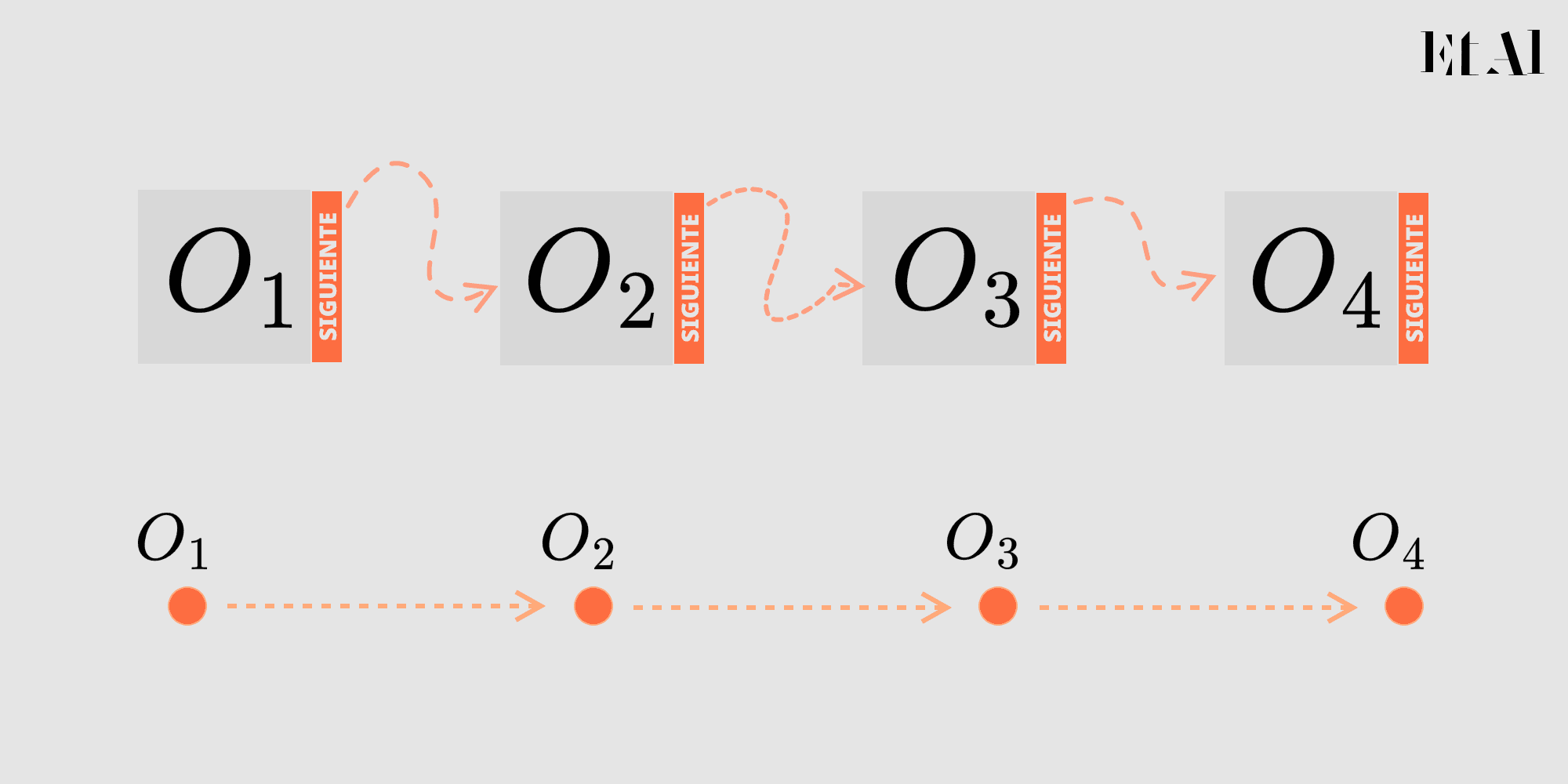
Podemos ver a una lista enlazada como una trayectoria dirigida cuyos vértices son objetos de cierta colección.
Una lista doblemente enlazada es exáctamente lo que te imaginas, añadimos un apuntador a cada objeto que nos indica cual es su antecesor.
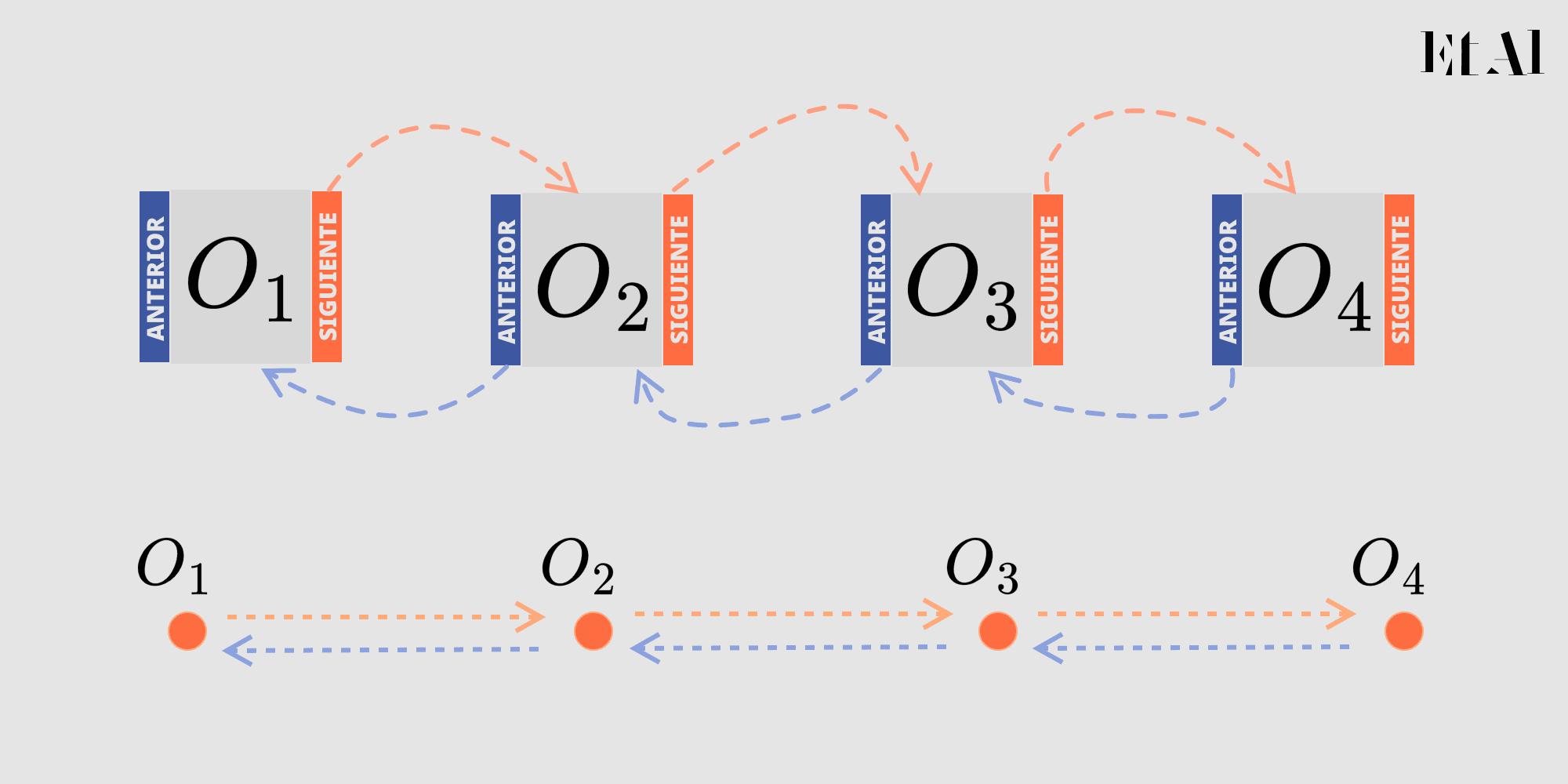
Finalmente, una lista doblemente enlazada y cíclica surge cuando conectamos el inicio con el final y el final con el inicio, o algo así dijo Nietzsche.
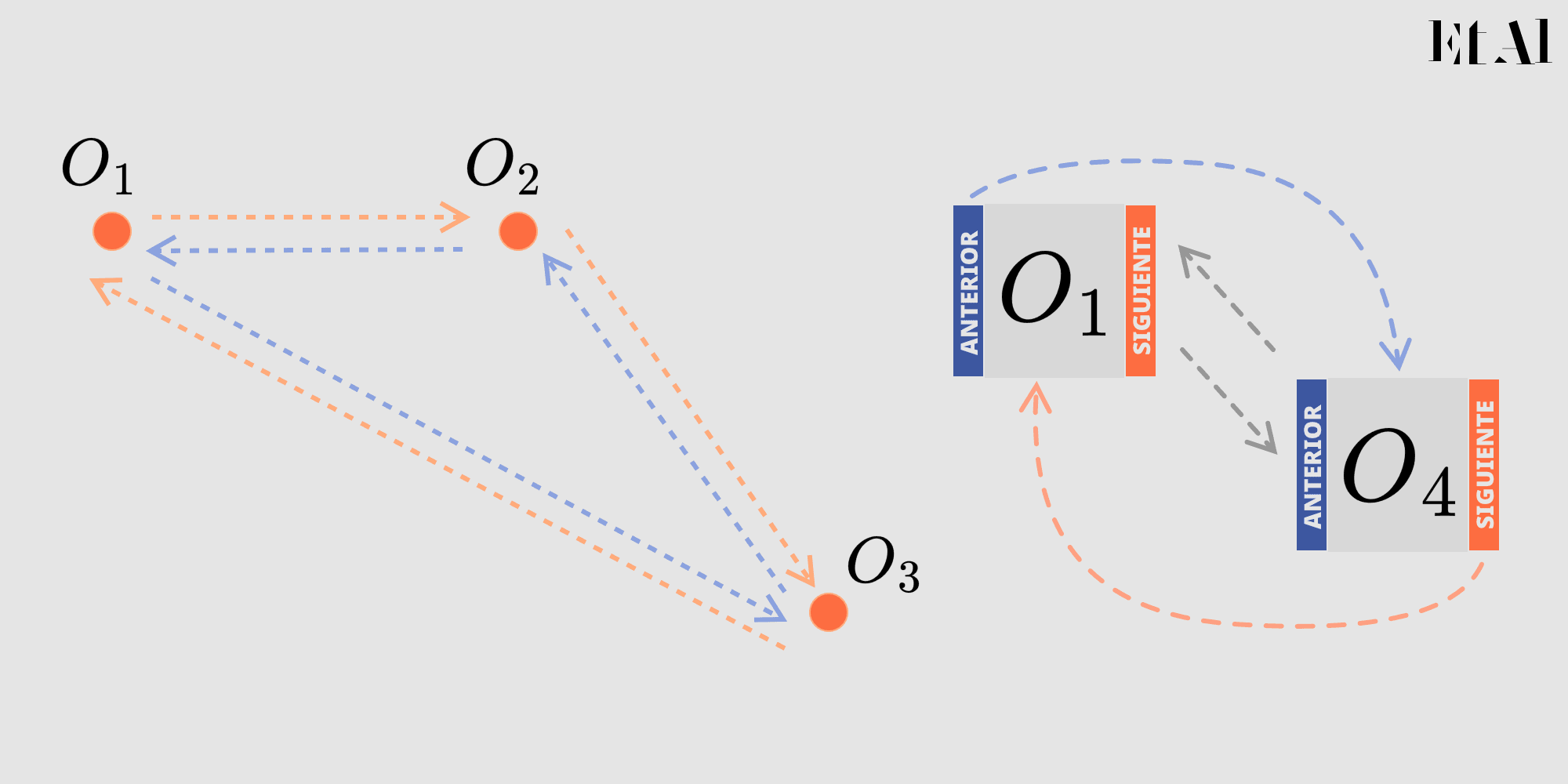
De ahora en adelante usaremos únicamente la representación como gráficas.
Esta estructura de datos tiene propiedades bastante interesantes, así que hagamos algunas observaciones alrededor de las capacidades de esta estructura.
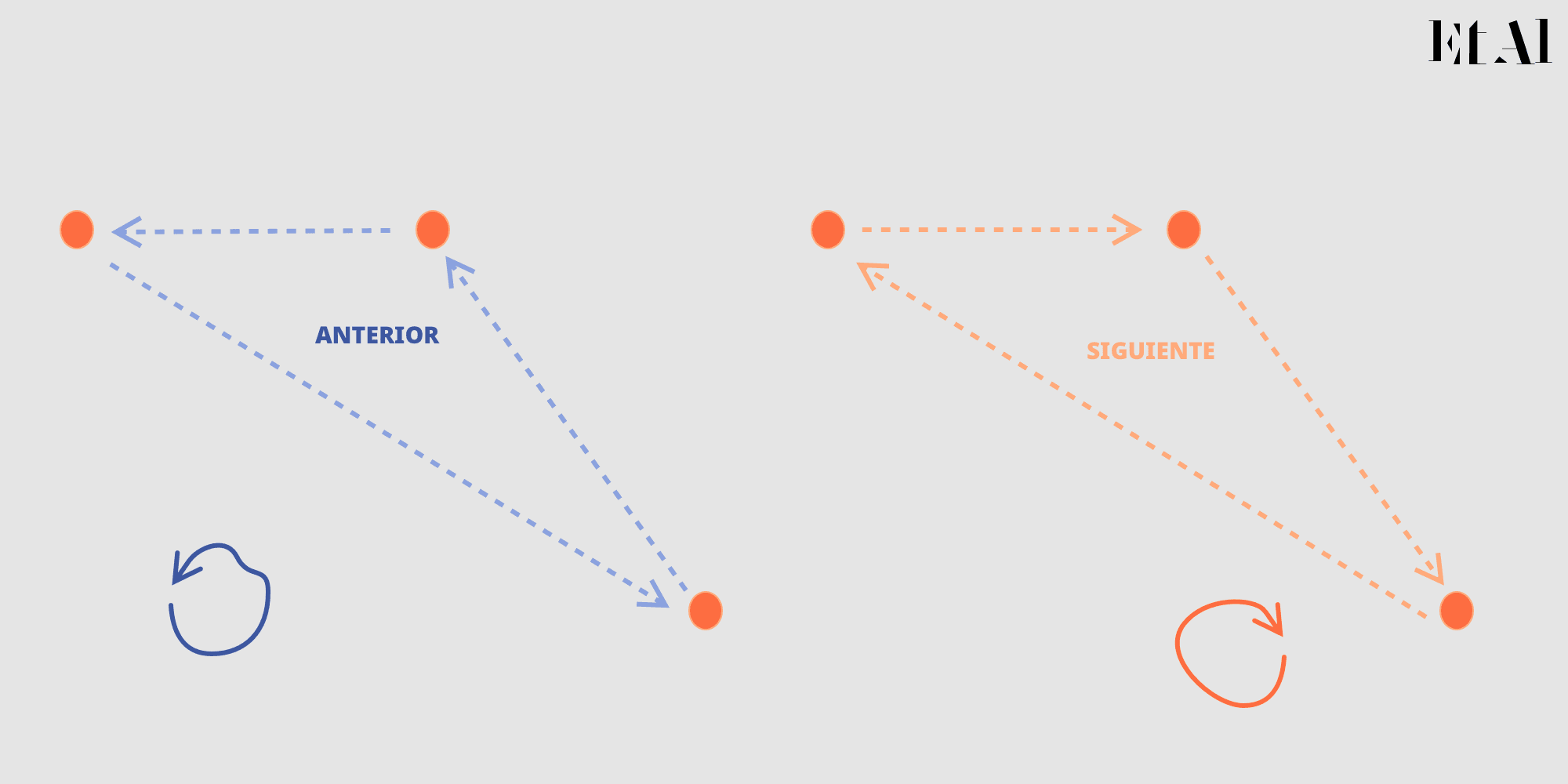
Codifica orientación
Si comienzas a seguir el apuntador siguiente entonces recorrerás el ciclo en el sentido de las manecillas del reloj, si sigues el apuntador anterior, rotarás en el sentido opuesto, de modo que conservamos una propiedad topológica muy importante mediante una estructura extremadamente simple.
Delimita regiones
Si imaginamos por un momento que esta colección de objetos y apuntadores es de hecho una gráfica dirigida y que esta gráfica dirigida está metida en el plano, entonces nuestros dos ojos nos hacen ver que divide el plano en dos regiones, el interior y exterior (no podría llamarme matemático si fallo en mencionar el Teoréma de Curva de Jordan y la inextricable dificultad de demostrarlo sin utilizar Homología).
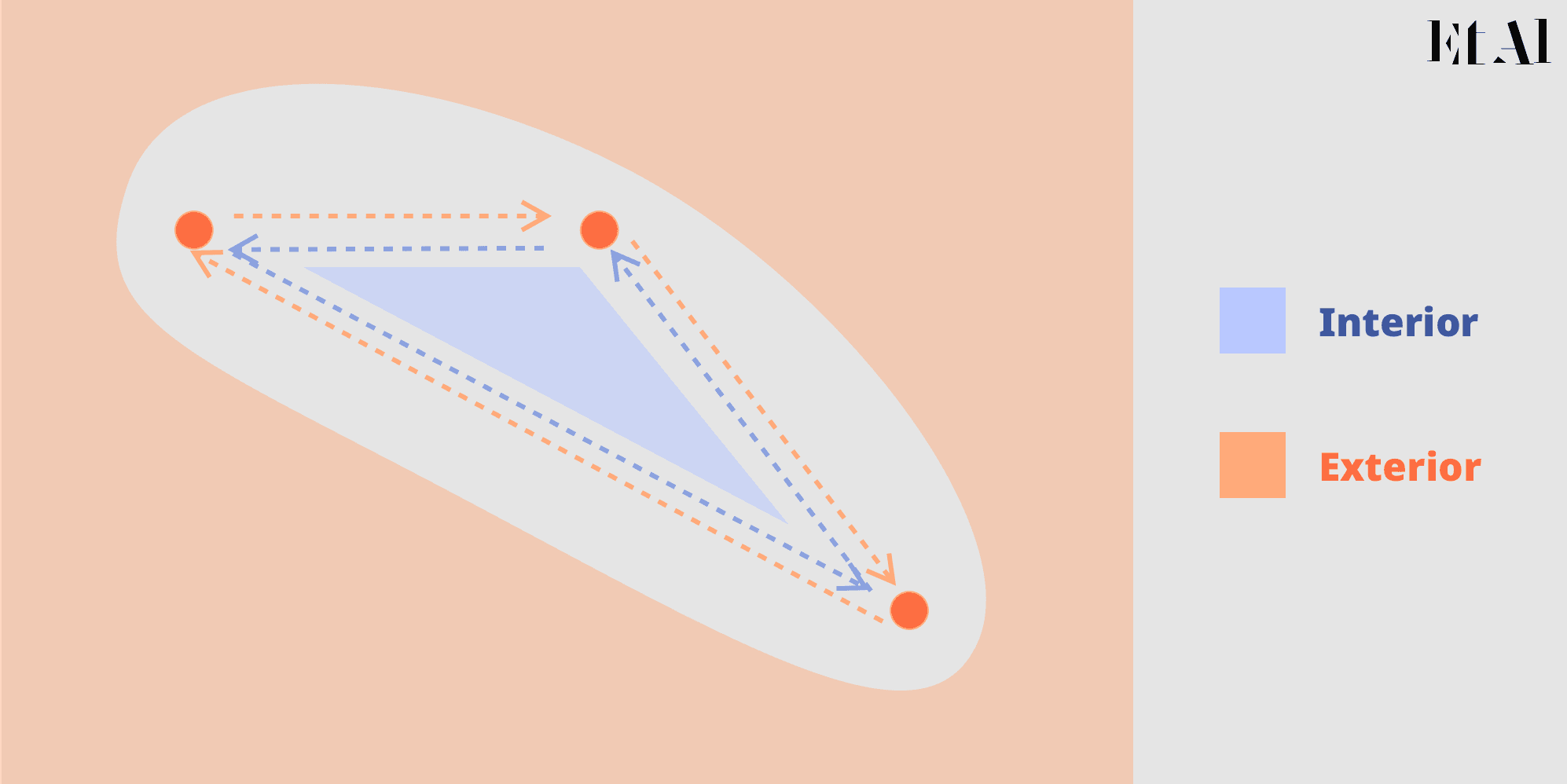
Pensando en implementación, podemos crear un objeto y asignar para cada flecha un apuntador a si esa flecha delimita una cara y a un objeto nulo de lo contrario.
Facilita la composición
Si tenemos dos de estas gráficas, podemos pegarlas de manera sencilla a lo largo de una arista simplemente eliminando las flechas que apuntan en sentido contrario.
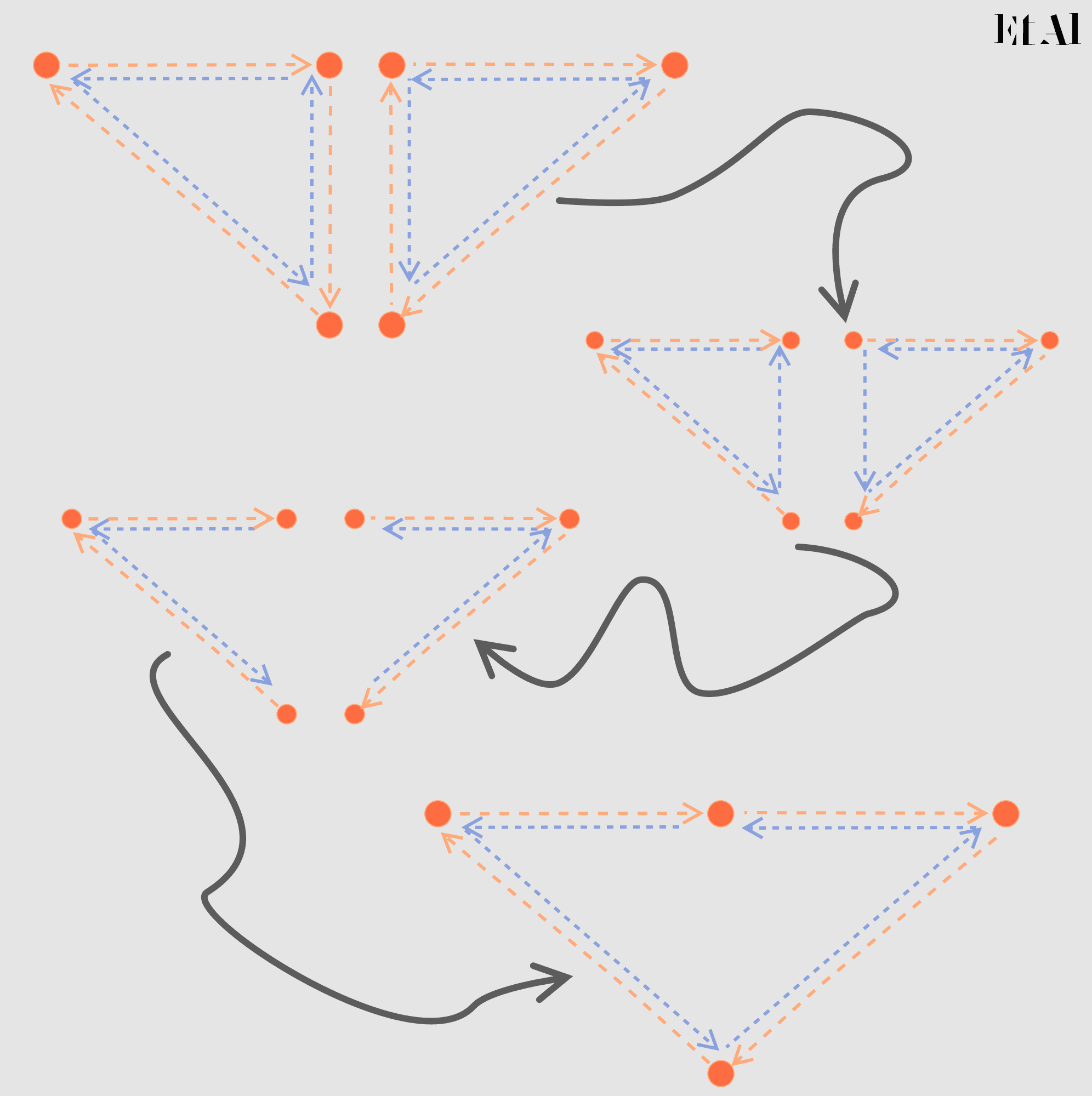
Este proceso mantiene las dos propiedades mencionadas anteriormente, esto es, la gráfica resultante mantiene la orientación de los dos ciclos dirigidos y sigue dividiendo al plano en dos regiones.
¿Y cuál es el beneficio de hacer esto?
Simple, intentemos de nuevo borrar un vértice. Para esto solo tenemos que actualizar dos apuntadores, lo cual es un Leetcode fácil, sin exagerar.
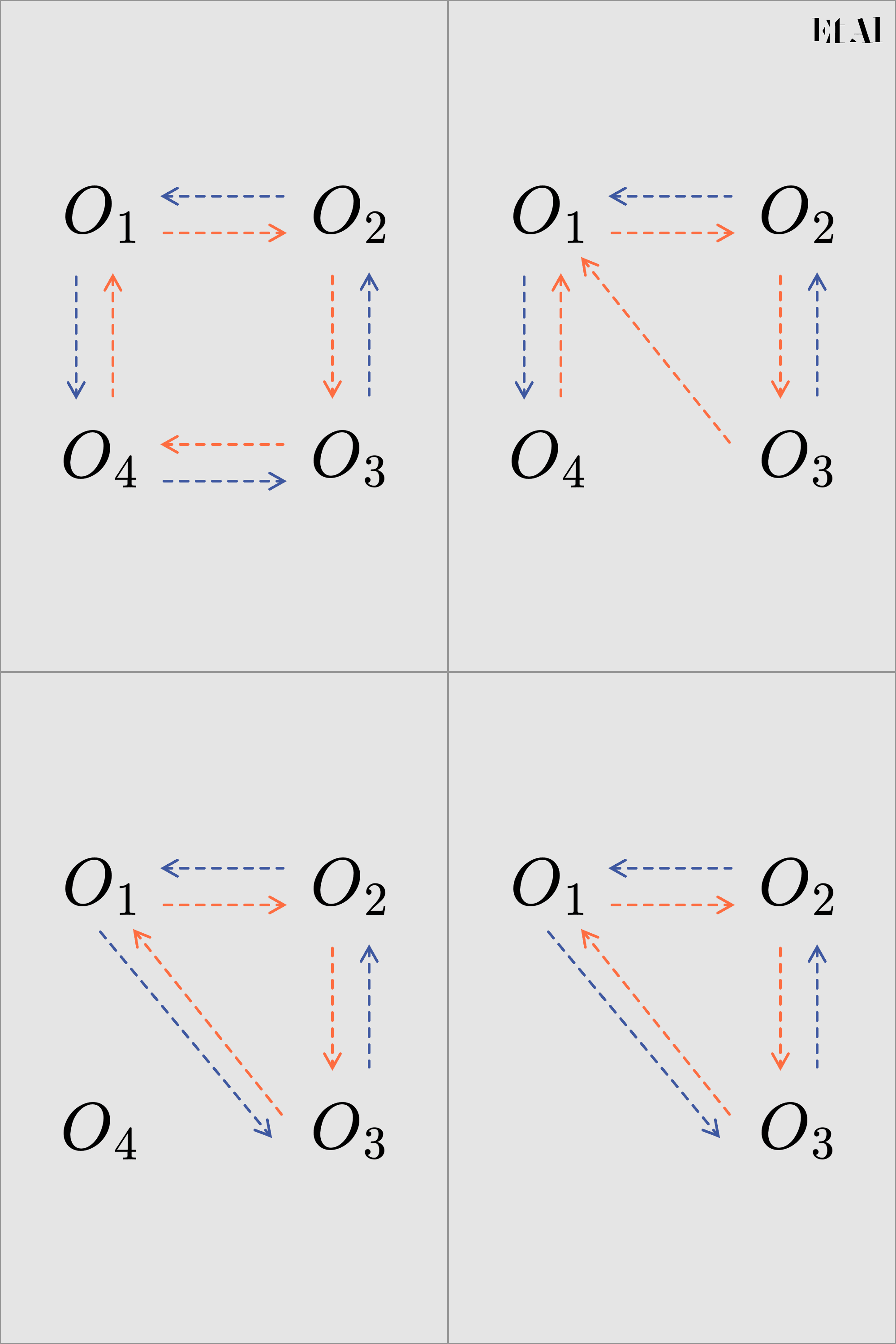
Esto sucede en tiempo constante, lo cual es un salto increíble en complejidad comparado con la representación matricial.
Recapitulando
En este breve post hemos revisado cómo representar un complejo simplicial de dos maneras y comparamos sus costos, vemos que existe una forma muy conveniente de representar superficies combinatorias tridimensionales usando listas doblemente enlazadas y cíclicas.
En el siguiente artículo escribiré sobre cómo implementar esta estructura de datos.
Hace unos ayeres hice una pequeña librería en c++ que serviría como kernel geométrico para mi motor gráfico de modelado procedural3, no garantizo que sea una gran implementación pero estas ideas son tan naturales que existe una única forma de implementarles.
Dicho esto, nos leemos pronto.